

22 Jun In many cases, artificial intelligence, machine learning and data analytics actually are simply statistics
This article by Shahab Mohaghegh, Professor of Petroleum and Natural Gas Engineering at West Virginia University in a publication by the Society of Petroleum Engineers (https://pubs.spe.org/en/dsde/dsde-article-detail-page/?art=6215) provides good perspective about what constitutes Artificial Intelligence (AI) and Machine Learning (ML). The article suggests that much of what is labelled AI or ML or even data analytics is in fact traditional statistics in the form of linear, non-linear or multivariate regression (or some combination thereof). While the focus of this article is the oil and gas industry, I suspect that the same is true of many industries.
Quoting from the article:
While traditional statistics tests hypotheses through parametric models and compares them to the standard metrics of the models, AI and ML builds models using the data instead of starting with a model and testing the data to see if it fits the predetermined models….
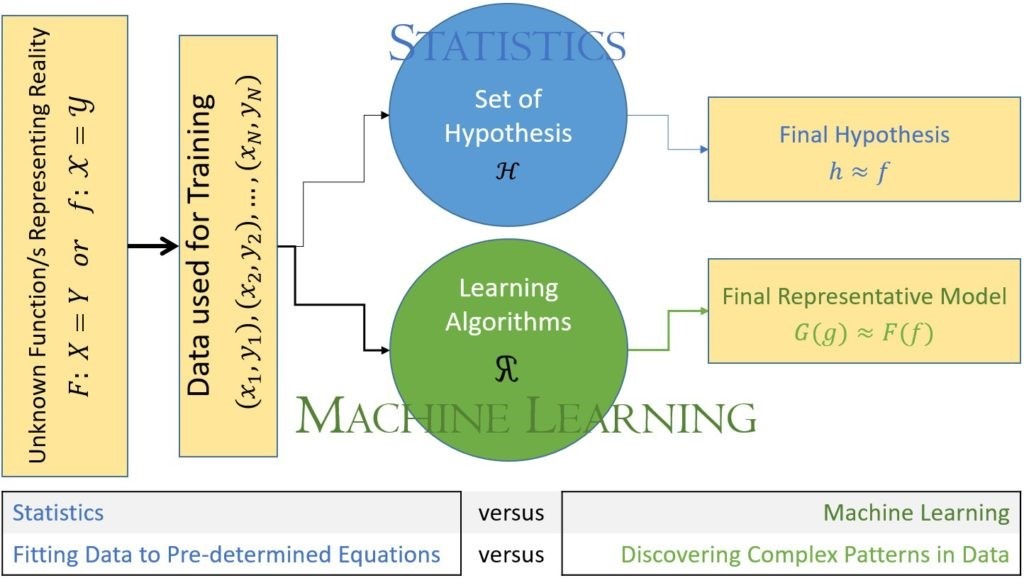
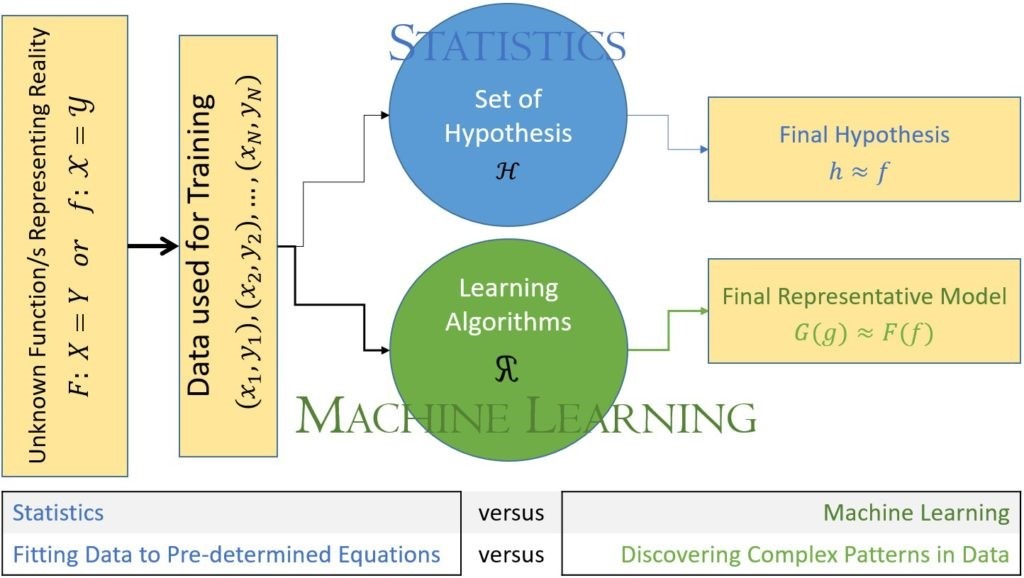
Statistical approach starts with a series of predetermined equations (set of hypotheses) such as single or multi-variable linear regression or nonlinear regression that is well defined (e.g., logarithmic, exponential, quadratic). Then, it tries to find the most appropriate predetermined equation that would fit the collected data.
AI and ML do not start with any predetermined models or equations. They [do] not start with any assumptions regarding the type of behavior that variables may have in order to correlate them to the target output. The characteristics of AI and ML is to discover patterns from the existing data. The strength of the open AI and ML algorithms has to do with their amazing capabilities to discover highly complex patterns within the large amounts of variables…
[The figure below] summarizes one of the major differences between traditional statistical approach to problem solving with the approach that is used by AI and ML. When data is used in the context of traditional statistical approaches, a series of predetermined equations are used in order to find out how to fit the data. In other words, the form and shape of the equation that will be fitting the data set and sometimes even the form of the data distributions are all predetermined. In such cases, if the actual data is too complex to fit any predetermined equations or distributions, then either the approach to solving the problem comes to a standstill or large number of assumptions, simplifications, and biases are incorporated into the data (or the problem) in order to come to some sort of a solution.
In short, there is no reason to think that AI or ML are inherently superior to traditional statistics. Instead, AI and ML are another set of tools that can be used together with traditional statistics (and other mathematical tools) to provide even better understandings of and solutions to problems. Not surprisingly, the set of tools to use is a matter of judgment on a case-by-case basis which, as is frequently the case, means that it is your team that is the key.
No Comments